
Latest News
Abstract
GPU kernel optimization is fundamental to modern deep learning but remains a specialized task requiring deep hardware expertise. Existing CUDA code generation approaches either rely on training-free refinement or fixed execution-feedback loops, which limits intrinsic optimization ability.
We present CUDA Agent, a large-scale agentic reinforcement learning system with three core components: scalable data synthesis, a skill-augmented CUDA development environment with reliable verification and profiling, and RL algorithmic techniques for stable long-context training.
CUDA Agent achieves state-of-the-art results on KernelBench, delivering 100%, 100%, and 92% faster rate over torch.compile on Level-1, Level-2, and Level-3 splits.
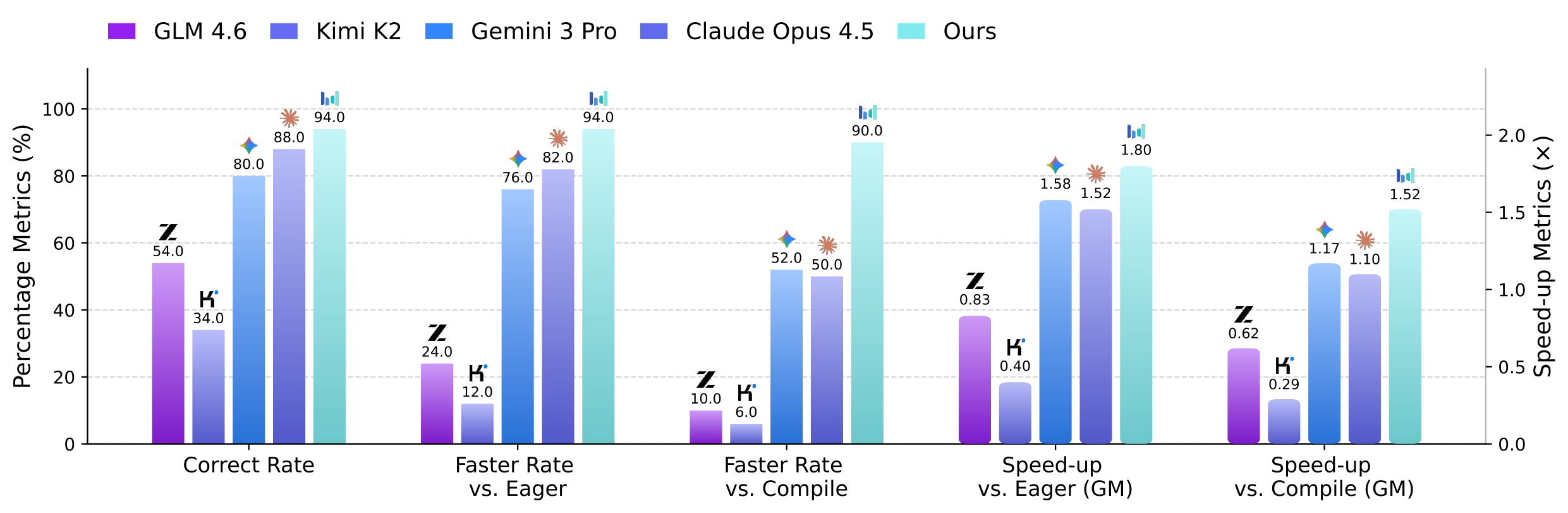
KernelBench comparison against torch.compile and strong proprietary models.
Key Contributions
Large-Scale Agentic RL System for CUDA Optimization
We introduce CUDA Agent, a large-scale agentic reinforcement learning system that improves intrinsic CUDA kernel generation and optimization ability through scalable synthesis, a skill-augmented environment, and stable long-horizon training.
State-of-the-Art KernelBench Performance
CUDA Agent achieves state-of-the-art results on KernelBench, delivering strong faster-than-compile rates across all levels and outperforming strong proprietary models on the hardest Level-3 setting.
Data Release: CUDA-Agent-Ops-6K
We release CUDA-Agent-Ops-6K, a high-quality synthesized training dataset with filtering and contamination control, supporting reproducible research on RL-based CUDA kernel optimization.
System Pipeline
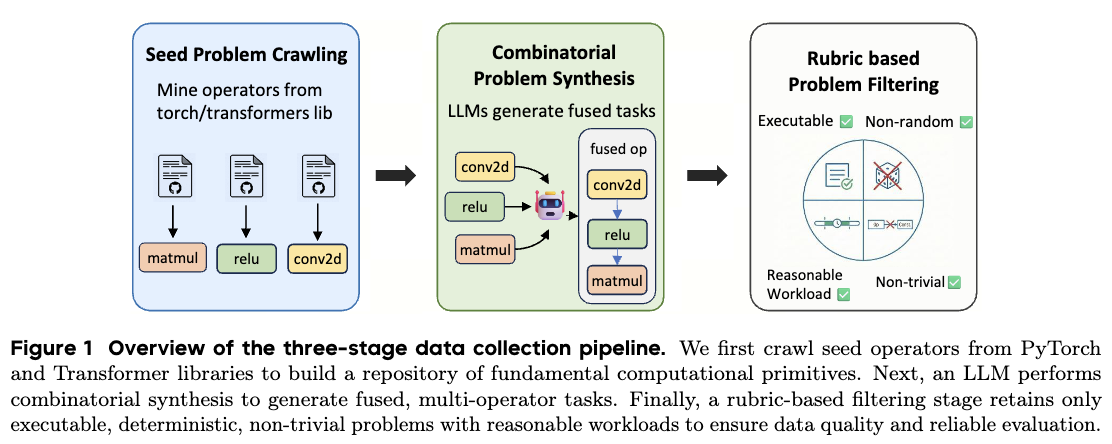
Data Synthesis
We build training tasks with a three-stage pipeline: seed problem crawling, LLM-based combinatorial
synthesis, and execution-driven filtering. Seed operators are mined from torch and
transformers, each represented as a Python class with initialization and forward methods.
- Combinatorial synthesis samples up to 5 torch operators and composes them sequentially into fused tasks.
- Filtering keeps only tasks that run in both eager and compile modes and removes stochastic operators.
- Anti-hacking checks remove constant or indistinguishable outputs across different inputs.
- Workload control keeps eager runtime in the 1ms-100ms range and removes high-similarity KernelBench cases.
The final curated dataset contains 6,000 training samples (CUDA-Agent-Ops-6K), designed for scalable RL training with broad task diversity and reduced contamination risk.
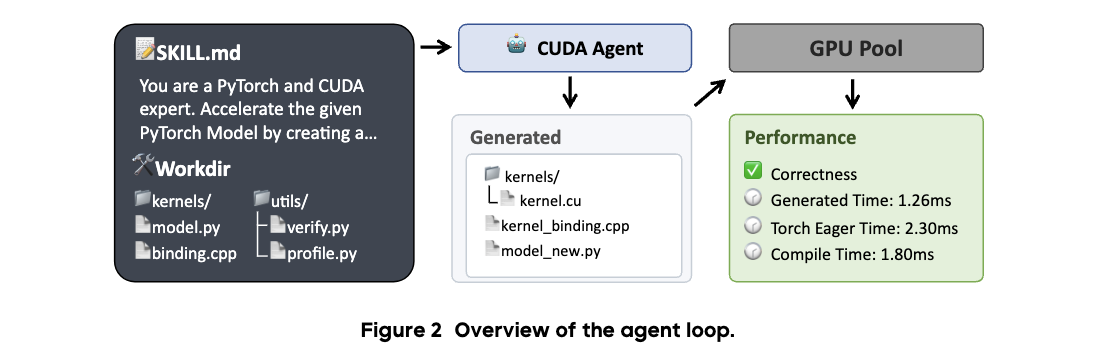
Agent Environment
The agent loop follows a ReAct-style workflow with coding tools and a CUDA skill specification (SKILL.md), enabling iterative coding, compile-debug cycles, and profiler-guided optimization.
- Standard workflow: profile native PyTorch, implement CUDA kernels/bindings, compile in GPU sandbox, iterate.
- Target requirement: pass correctness checks and exceed a 5% speedup over
torch.compile. - Robust reward schedule uses milestone-based discrete rewards for correctness and speed gains.
- Anti-reward-hacking controls: protected verify/profile scripts, forbidden fallback calls, 5-input correctness checks, synchronized warm-up profiling, no web retrieval.
These constraints provide reliable execution-based feedback so policy learning emphasizes true kernel quality rather than shortcut behaviors.
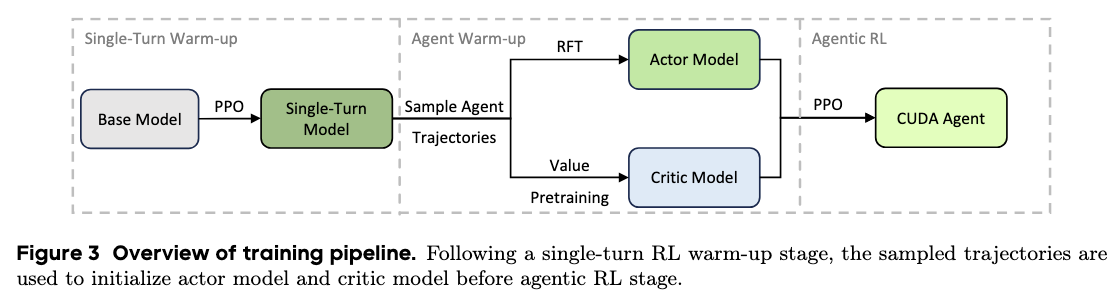
Training Pipeline
Training is staged to stabilize long-horizon RL for CUDA coding. We first run single-turn PPO warm-up, then initialize both actor and critic before full multi-turn agentic RL.
- Single-turn warm-up improves base CUDA generation before entering interactive agent training.
- Actor initialization uses Rejection Fine-Tuning (RFT) on sampled trajectories with positive outcomes.
- RFT filtering removes inefficient loops and invalid tool-call patterns to reduce policy collapse risk.
- Critic initialization uses value pretraining so advantage estimates are reliable from early steps.
With this multi-stage design, training remains stable for long-context settings (up to 128k context, 150 training turns, and up to 200 turns during evaluation), enabling sustained reward growth.
Main Results
We report full metrics for both Overall and Level-3 splits on KernelBench: Pass Rate, Faster Rate (vs. Eager / vs. Compile), and Geomean Speed-up (vs. Eager / vs. Compile).
Overall
Level-3
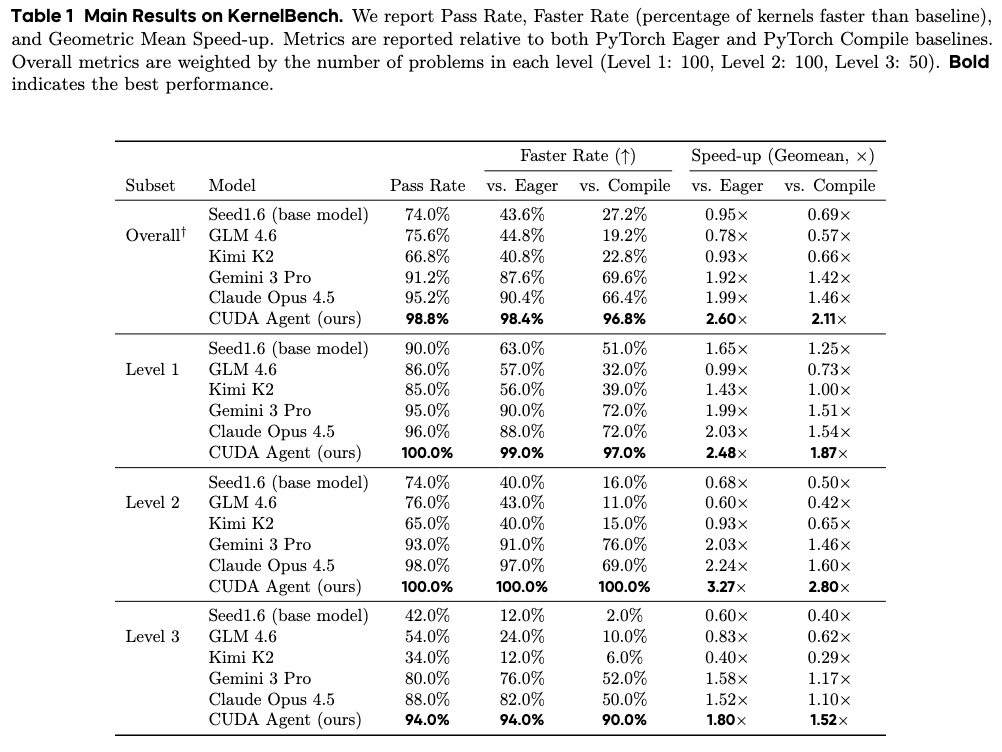
Overall performance and speedup metrics on KernelBench.
Citation
If you use CUDA Agent in your research, please cite:
@article{cudaagent2026,
title = {CUDA Agent: Large-Scale Agentic RL for High-Performance CUDA Kernel Generation},
author = {Dai, Weinan and Wu, Hanlin and Yu, Qiying and Gao, Huan-ang and Li, Jiahao and Jiang, Chengquan and Lou, Weiqiang and Song, Yufan and Yu, Hongli and Chen, Jiaze and Ma, Wei-Ying and Zhang, Ya-Qin and Liu, Jingjing and Wang, Mingxuan and Liu, Xin and Zhou, Hao},
journal = {arXiv preprint},
year = {2026}
}